Verwenden Sie Java Jsoup Parsing HTML
1. Was ist Jsoup?
Jsoup ist Java HTML Parser. In anderen Worten, Jsoup ist eine Bibliothek zur Analyse des HTML Dokument. Jsoup bietet die API zur Aufnahme der Daten und Daten- Bearbeitung aus URL oder aus der Datei HTML an. Es benutzt die Methode wie DOM, CSS , JQuery um die Daten aufzunehmen und bearbeiten.

Sehen Sie bitte ein Beispiel mit Jsoup:
HelloJsoup.java
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class HelloJsoup {
public static void main( String[] args ) throws IOException{
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}2. Die Jsoup Bibliothek
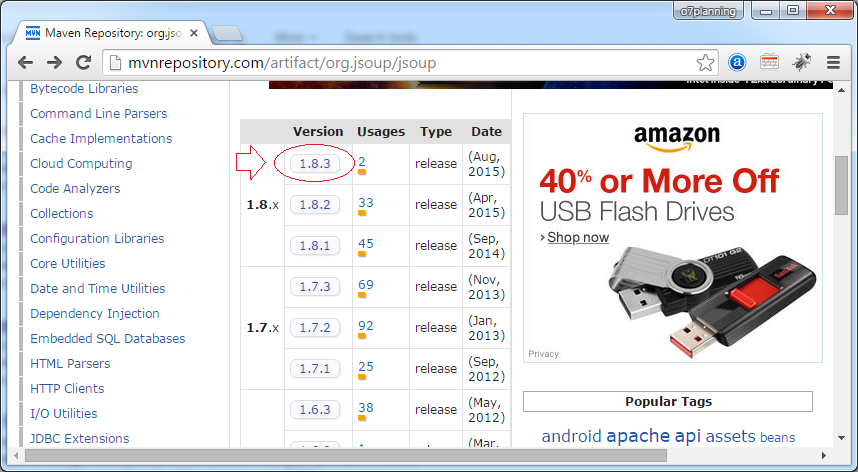
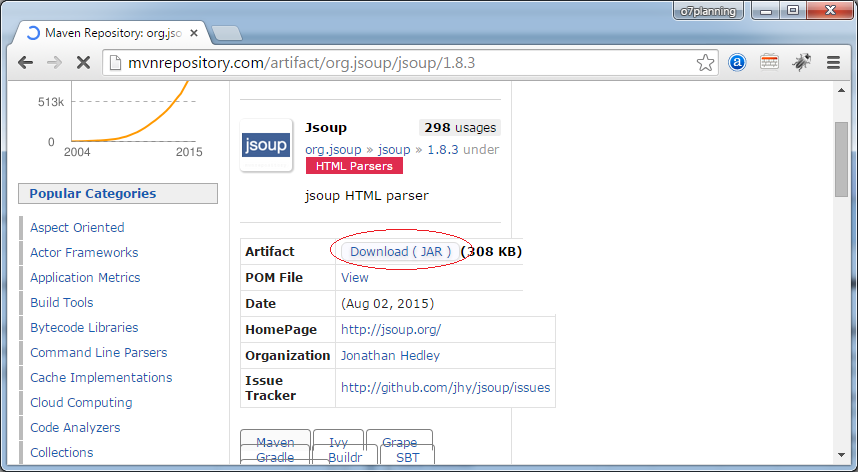
Sie können Maven benutzen oder die Bibliothek Jsoup mit der Format von File Jar herunterladen
Mit Maven
<!-- http://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>Oder Sie können herunterladen
3. Jsoup API
Jsoup schließt viele Klasse ein, aber es gibt 3 wichtigste Klasse. Das sind
- org.jsoup.Jsoup
- org.jsoup.nodes.Document
- org.jsoup.nodes.Element
- Jsoup.java
Die Methode | Die Bezeichnung |
static Connection connect(String url) | Das Objekt Connection verbindent mit URL erstellen und zurückgeben |
static Document parse(File in, String charsetName) | Eine File HTML mit charset annalysieren. |
static Document parse(File in, String charsetName, String baseUri) | Die File HTML mit charset,und baseUri annalysieren |
static Document parse(String html) | Die Kode HTML annalysieren und das Objekt Document zurückgeben. |
static Document parse(String html, String baseUri) | Die Kode HTML mit baseUri zum Objekt Document annalysieren |
static Document parse(URL url, int timeoutMillis) | Eine URL zum Document annalysieren |
static String clean(String bodyHtml, Whitelist whitelist) | Die sichere HTML aus der Input-HTML zurückgeben, indem die Input-HTML wird annalysiert und durch eine Weißliste (whitelist) des Tags und der erlaubten Attribute gefiltert |
- Document.java
Die Methode | Die Bezeichnung |
Element body() |
In den Element body vom HTML Dokument zugreifen
|
Charset charset() | charset zurückgeben, das im Unterlagen benutzt wird
|
void charset(Charset charset) | charset wird im Unterlagen benutzt.
|
Document clone() |
Eine Copy Version des Unterlagen erstellen, umfassend die SubNode kopieren
|
Element createElement(String tagName) |
Ein Element erstellen
|
static Document createShell(String baseUri) |
Ein leeres Unterlagen erstellen (Document) um die Element darin einzufügen
|
Element head() |
In den Element head zugreifen
|
String location() | URL des Dokument zurückgeben
|
String nodeName() |
Die Node des Name dieser Node zurückgeben
|
Document normalise() |
Normalise the document.
|
String outerHtml() | Outer HTML dieser node zurückgeben
|
Document.OutputSettings outputSettings() |
Das Objekt als die Inputeinstellungen des Dokument zurückgeben
|
Document outputSettings(Document.OutputSettings outputSettings) |
Das Output des Dokument einstellen.
|
Document.QuirksMode quirksMode() | |
Document quirksMode(Document.QuirksMode quirksMode) | |
Element text(String text) |
Die Inhalt der Text vom body des Dokument einstellen
|
String title() |
Den Titel des Dokument zurückgeben
|
void title(String title) |
Den Titel des Dokument setzen
|
boolean updateMetaCharsetElement() |
Es ist true wenn der Element (element) mit der Information charset im Dokument durch die Methode Document.charset(Charset) geändert.
|
void updateMetaCharsetElement(boolean update) |
Ja oder nein einstellen. Der Element mit der Information charset werden durch die Methode Document.charset(Charset) aktualisiert.
|
- Element.java
4. Die Manipulation mit dem Document
Die Erstellung von Document aus URL
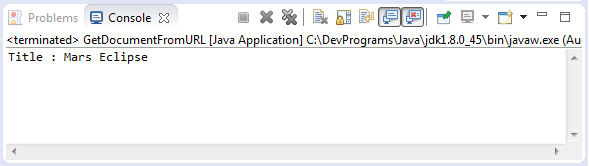
GetDocumentFromURL.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromURL {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://eclipse.org").get();
String title = doc.title();
System.out.println("Title : " + title);
}
}Das Beispiel starten
Die Erstellung vom Dokument aus der File
GetDocumentFromFile.java
package org.o7planning.tutorial.jsoup.document;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromFile {
public static void main(String[] args) throws IOException {
File htmlFile = new File("C:/index.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
String title = doc.title();
System.out.println("Title : " + title);
}
}Die Erstellung vom Dokument aus String
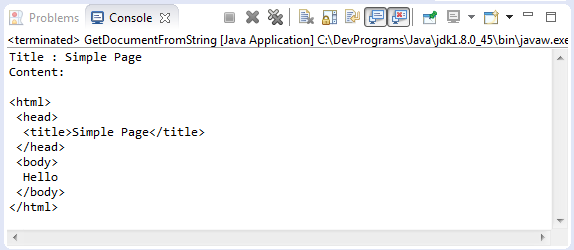
GetDocumentFromString.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class GetDocumentFromString {
public static void main(String[] args) throws IOException {
String htmlString = "<html><head><title>Simple Page</title></head>"
+ "<body>Hello</body></html>";
Document doc = Jsoup.parse(htmlString);
String title = doc.title();
System.out.println("Title : " + title);
System.out.println("Content:\n");
System.out.println(doc.toString());
}
}Das Beispiel starten
HTML Fragment analysieren
Ein genügendes Dokument HTML schließt Header und Body ein, manchmals brauchen Sie einen Stück von HTML analysieren. Und Sie können ein Dokument HTML mit header und body einnehmen. Bitte sehen Sie ein Beispiel
ParsingBodyFragment.java
package org.o7planning.tutorial.jsoup.document;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ParsingBodyFragment {
public static void main(String[] args) throws IOException {
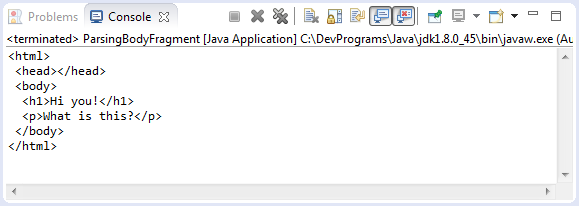
String htmlFragment = "<h1>Hi you!</h1><p>What is this?</p>";
Document doc = Jsoup.parseBodyFragment(htmlFragment);
String fullHtml = doc.html();
System.out.println(fullHtml);
}
}Ein Beispeil starten
5. Die DOM-Methoden
Jsoup hat einige Methode, die so ähnlich wie die Methode in das DOM Modell sein. (ein Modell zur Analyse von XML Dokument)
Die Methode | Die Bezeichnung |
Element getElementById(String id) | Ein Element durch ID finden, einschließend oder unter des Element. |
Elements getElementsByTag(String tag) | Die Elemente finden, einschließend und die Rekursion unter des Element mit den bestimmten Namentag |
Elements getElementsByClass(String className) | Ein Element finden, das className durch den Parameter hat, einschließend oder unter des Element |
Elements getElementsByAttribute(String key) | Ein Element finden, das das Attribut durch den Parameter ohne den Unterschied zwischen großen oder kleinen Buchstaben hat |
Elements siblingElements() | Die Geschwester-Elemente zurückgeben |
Element firstElementSibling() | Das erste Geschwester-Element von diesem Element zurückgeben |
Element lastElementSibling() | Das letzte Geschwester-Element von diesem Element zurückgeben |
...... | |
Einige Methode zur Einnahme von Daten auf Element
Die Methode | Die Bezeichnung |
String attr(String key) | Die Attributeswert durch seinen Schlüssel (key) zurückgeben |
void attr(String key, String value) | Die Attributeswert setzen. Wenn das Attribut existiert, wird es ersetzt. |
String id() | Das ID Attribut zurückgeben wenn ja oder das leere String zurückgeben wenn nicht |
String className() | Das Wertsstring des Attribut "class". Es kann viele Klassename haben, die durch den leeren Zeichen getrennt werden (Zum Beispiel <div class="header gray"> gibt es "header gray" zurück) |
Set<String> classNames() | Alle Klasse-names zurückgeben. Z.B <div class="header gray">, gibt es 2 Elemente "header" und "gray" zurück. Achten Sie, die Änderung der Kollektion macht das Attribut des Element nicht ändern. Wenn ändern möchten, benutzen Sie die Methode classNames(java.util.Set). |
String text() | Eine Kombinationstext von seiner Text und alle Text von der Sub-Elementen zurückgeben |
void text(String value) | Die Text für das Element setzen |
String html() | Retrieves the element's inner HTML. Z.B <div><p>a</p> , gibt es <p>a</p> zurück. (Node.outerHtml() wird <div><p>a</p></div> zurückgeben) |
void html(String value) | Html innerhalb des Elementes setzen. die verfügbaren HTML löschen |
Tag tag() | Tag für das Element zurückgeben |
String tagName() | Den Tagname für das Element zurückgeben. Z.B div |
...... | |
Die Methode benutzen HTML
Die Methode | Die Bezeichnung |
Element append(String html) | HTML in das Element einfügen. Die angebotene Html wird analysiert und jede Node wird am Ende von der Sub-Node des Element angehängt |
Element prepend(String html) | HTML in das Element einfügen. Die angebotene Html wird analysiert,und jede Node wird vor der Sub-Node des Element angehängt |
Element appendText(String text) | Eine neue TextNode in das Element erstellen und anhängen |
Element prependText(String text) | Eine neue TextNode vor der Kollektion von Sub-Node des Element erstellen und anhängen |
Element appendElement(String tagName) | Ein neues Element durch TagName erstellen und als das Sub-Element am Ende anhängen |
Element prependElement(String tagName) | Ein neues Element durch TagName erstellen und als das erste Sub-Element anhängen |
Element html(String value) | HTML innerhalb des Element setzen. die verfügbaren HTML löschen |
...... | |
Das Beispiel bezeichnet die Benutzung der Methode DOM und die Analyse des HTML Dokument zum Aufschreiben der Information in dem Tag form.
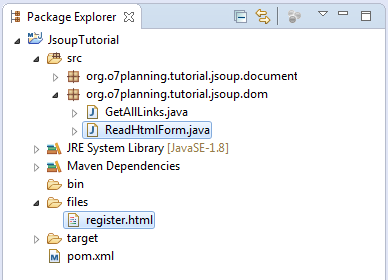
register.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Register</title>
</head>
<body>
<form id="registerForm" action="doRegister" method="post">
<table>
<tr>
<td>User Name</td>
<td><input type="text" name="userName" value="Tom" /></td>
</tr>
<tr>
<td>Password</td>
<td><input type="password" name="password" value="Tom001" /></td>
</tr>
<tr>
<td>Email</td>
<td><input type="email" name="email" value="theEmail@gmail.com" /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" name="submit" value="Submit" /></td>
</tr>
</table>
</form>
</body>
</html>ReadHtmlForm.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
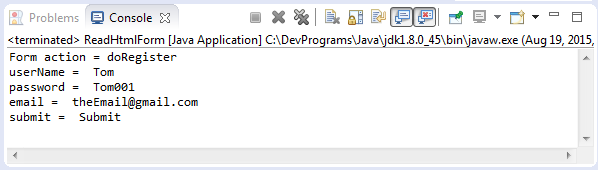
public class ReadHtmlForm {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.parse(new File("files/register.html"), "utf-8");
Element form = doc.getElementById("registerForm");
System.out.println("Form action = "+ form.attr("action"));
Elements inputElements = form.getElementsByTag("input");
for (Element inputElement : inputElements) {
String key = inputElement.attr("name");
String value = inputElement.attr("value");
System.out.println(key + " = " + value);
}
}
}Das Beispiel starten
GetAllLinks.java
package org.o7planning.tutorial.jsoup.dom;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
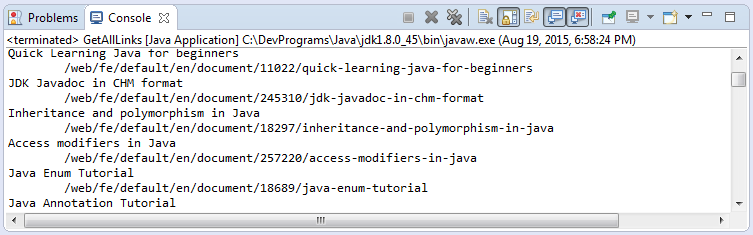
public class GetAllLinks {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("http://o7planning.org").get();
// Elements extends ArrayList<Element>.
Elements aElements = doc.getElementsByTag("a");
for (Element aElement : aElements) {
String href = aElement.attr("href");
String text = aElement.text();
System.out.println(text);
System.out.println("\t" + href);
}
}
}Das Beispiel starten
6. Die ähnlichen Methoden wie jQuery, Css
Möchten Sie die Elemente, die die Syntax wie CSS oder jQuery benutzen, suchen oder einsetzen?
JSoup bietet Sie einige Methode zur Durchführung dieser Aufgaben
- Element.select(String selector)
- Elements.select(String selector)
Das Beispiel
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// a with href
Elements links = doc.select("a[href]");
// img with src ending .png
Elements pngs = doc.select("img[src$=.png]");
// div with class=masthead
Element masthead = doc.select("div.masthead").first();
// direct a after h3
Elements resultLinks = doc.select("h3.r > a");Die Elemente JSoup unterstützen Ihnen die Syntax wie CSS oder JQuery damit Sie die entsprechenden Elemente suchen. Diese Unterstützungen sind sehr stark. Die Options sind vorhanden in der Klasse von Document, Element oder Elements.
Die Übersicht von dem Selector (Der Wähler).
Selector | Die Bezeichnung |
tagname | Die Elemente nach den Tag-name. Zum Beispiel: a |
ns|tag | Die Elemente nach den Tag-name in einer namespace, zum Beispiel: fb|name bedeutet die Findung nach den Elemente <fb:name> |
#id | Die Elemente nach ID finden, zum Beispiel #logo |
.class: | Die Elemente nach den Klasse-name finden ,zum Beispiel .masthead |
[attribute] | Die Elemente mit den Attribute, zum Beispiel [href] |
[^attr] | Die Elemente mit den Attribute, die mit.. beginnen , zum Beispiel [^data-] findet die Elemente mit den Attribute, die mit data- beginnen |
[attr=value] | Die Elemente mit den Attribute-Wert, z.B [width=500] (kann die Anführungzeichen benutzen) |
[attr^=value], [attr$=value], [attr*=value] | Die Elemente mit den Attribute-Wert, die mit... beginnen, enden oder die Wert enthalten , zum Beispiel [href*=/path/] |
[attr~=regex] | Die Elemente, deren Wert den regularen Ausdrück entsprechen, zum Beispiel img[src~=(?i)\.(png|jpe?g)] |
* | Alle Elemente, zum Beispiel * |
Der verbindende Selector
Selector | Die Bezeichnung |
el#id | Die Elemente mit ID, zum Beispiel div#logo |
el.class | Die Elemente mit der Klasse , zum Beispiel div.masthead |
el[attr] | Die Elemente mit den Attribute, zum Beispiel a[href] |
die irgendeine Kombination, Zum Beispiel a[href].highlight | |
ancestor child | (Das Vorängerelement und das Nachkommenelement) die Nachkommenelemente eines Element, zum Beispiel: .body p findet irgendeine p Elemente, die die Nachkommenelemente mit dem Attribut class = "body" ist |
parent > child | Die direkte Sub-Elemente des Vaterelement, zum Beispiel div.content > p findet die Elemente p als die direkte Sub-Elemente von div mit der Klasse class ='content'; und body > * |
siblingA + siblingB | Die Geschwesterelement B gleich vor dem Element A, zum Beispiel div.head + div finden |
siblingA ~ siblingX | Die Geschwesterelement X vor dem Element A finden, zum Beipsiel h1 ~ p |
el, el, el | Die Gruppe von mehreren Selector finden die Elemente, die den Selector entsprechen, finden. Zum Beispiel div.masthead, div.logo |
Pseudo selectors
Selector | Die Bezeichnung |
:lt(n) | Die Elemente finden, deren Geschwestersindex (Die Position im DOM Baum bezieht sich mit seiner Vater) kleiner als n ist; zum Beispiel td:lt(3) |
:gt(n) | Die Element finde, deren Geschwestersindex größer als n ist, zum Beispiel div p:gt(2) |
:eq(n) | Die Elements finden, deren Geschwestersindex so gleich wie n ist ;z.B. form input:eq(1) |
:has(seletor) | Die Elemente finden, deren Element dem Selector entsprechen ; z.B div:has(p) |
:not(selector) | Die Elemente finden, deren Element dem Selector nicht entsprechen, z.B div:not(.logo) |
:contains(text) | Die Elemente finden, die die gegebene Text enthaltet. die Findung unterscheidet sich die größe und kleine Buchstabe nicht ; z.B p:contains(jsoup) |
:containsOwn(text) | Die Elemente finden, die die gegebene Text direkt enthaltet |
:matches(regex) | Die Elemente finden, deren Text dem bestimmten regularen Ausdruck entsprechen ; z.B div:matches((?i)login) |
:matchesOwn(regex) | Die Elemente finden, deren eigenen Text dem bestimmten regularen Ausdruck ensprechen |
Achtung: die Index pseudo wird vom 0 makiert. Das erste Element hat die Index 0, das zweite Element hat die Index 1 ,... | |
QueryLinks.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class QueryLinks {
public static void main(String[] args) throws IOException {
Connection conn = Jsoup.connect("http://o7planning.org");
Document doc = conn.get();
// Query <a> elements, href contain /document/
String cssQuery = "a[href*=/document/]";
Elements elements= doc.select(cssQuery);
Iterator<Element> iterator = elements.iterator();
while(iterator.hasNext()) {
Element e = iterator.next();
System.out.println(e.attr("href"));
}
}
}Das Ergebnis zum Beispiel-Starten
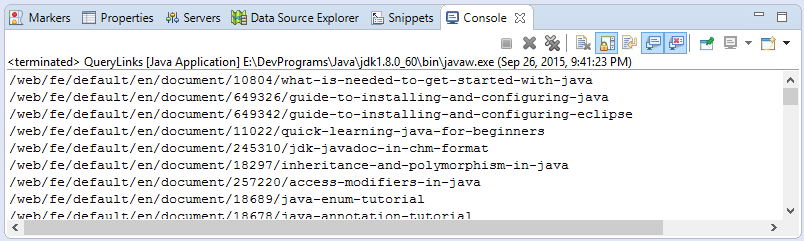
document.html
<html>
<head>
<title>Jsoup Example</title>
</head>
<body>
<h1>Java Tutorial For Beginners</h1>
<br>
<div id="content">
Content ....
</div>
<div class="related-container">
<h3>Related Documents</h3>
<a href="http://o7planning.org/web/fe/default/en/document/649342/guide-to-installing-and-configuring-eclipse">
Guide to Installing and Configuring Eclipse
</a>
<a href="http://o7planning.org/web/fe/default/en/document/649326/guide-to-installing-and-configuring-java">
Guide to Installing and Configuring Java
</a>
<a href="http://o7planning.org/web/fe/default/en/document/245310/jdk-javadoc-in-chm-format">
Jdk Javadoc in chm format
</a>
</div>
</body>
</html>SelectorDemo1.java
package org.o7planning.tutorial.jsoup.selector;
import java.io.File;
import java.io.IOException;
import java.util.Iterator;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SelectorDemo1 {
public static void main(String[] args) throws IOException {
File htmlFile = new File("document.html");
Document doc = Jsoup.parse(htmlFile, "UTF-8");
// First <div> element has class ="related-container"
Element div = doc.select("div.related-container").first();
// List the <h3>, the direct child elements of the current element.
Elements h3Elements = div.select("> h3");
// Get first <h3> element
Element h3 = h3Elements.first();
System.out.println(h3.text());
// List <a> elements, is a descendant of the current element
Elements aElements = div.select("a");
// Query the current element list.
// The element that href contains 'installing'.
Elements aEclipses = aElements.select("[href*=Installing]");
Iterator<Element> iterator = aEclipses.iterator();
while (iterator.hasNext()) {
Element a = iterator.next();
System.out.println("Document: "+ a.text());
}
}
}Das Ergebnis zum Beispiel-Starten
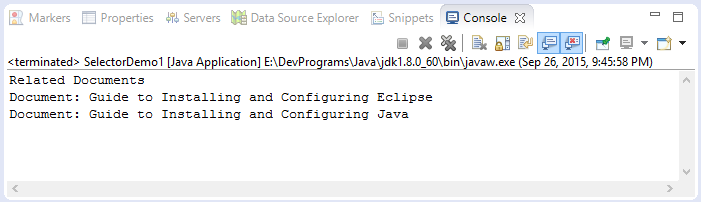
Java Open Source Bibliotheken
- Die Anleitung zu Java JSON Processing API (JSONP)
- Verwenden Sie Scribe OAuth Java API mit Google OAuth 2
- Hardware-Informationen in der Java-Anwendung abrufen
- Restfb Java API für Facebook
- Erstellen Sie Credentials für Google Drive API
- Die Anleitung zu Java JDOM2
- Die Anleitung zu Java XStream
- Verwenden Sie Java Jsoup Parsing HTML
- Rufen Sie geografische Informationen basierend auf der IP-Adresse mit GeoIP2JavaAPI ab
- Lesen und Schreiben von Excel-Dateien in Java mit Apache POI
- Entdecken Sie die Facebook Graph API
- Manipulieren von Dateien und Ordnern auf Google Drive mithilfe von Java
Show More