Die Anleitung zu Java OutputStreamWriter
1. OutputStreamWriter
OutputStreamWriter ist eine Unterklasse von Writer. Sie ist eine Brücke, damit Sie ein byte stream zu einem character stream umwandeln. Anders gesagt, Sie dürfen ein OutputStream zu einem Writer wandeln.
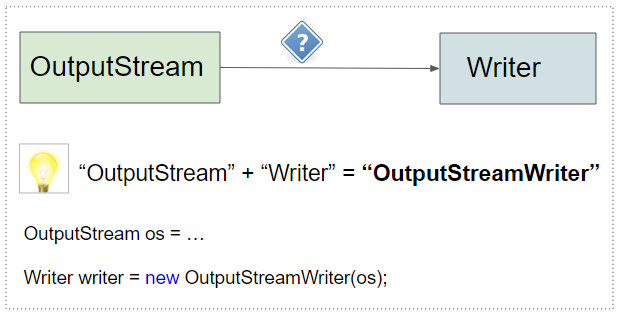
Tipp: Um einen "OutputStream" zu einen "Writer" umzuwandeln, müssen Sie nur diese 2 Wörter verketten, um "OutputStreamWriter" zu bilden, und dann Sie erhalten die Lösung.
OutputStreamWriter constructors
OutputStreamWriter(OutputStream out)
OutputStreamWriter(OutputStream out, String charsetName)
OutputStreamWriter(OutputStream out, Charset cs)
OutputStreamWriter(OutputStream out, CharsetEncoder enc)Außer der übergeordneten Klasse geerbten Methoden verfügt OutputStreamWriter über einige eigene Methoden.
Method | Description |
String getEncoding() | den Namen der Zeichenkodierung zurückgeben, die durch OutputStreamWriter verwendet wird. |
2. UTF-16 OutputStreamWriter
UTF-16 ist eine ziemlich übliche Kodierung (encoding) für Chinesischen oder japanischen Text. In diesem Beispiel werden wir analysieren, wie eine Datei mit der Kodierung UTF-16 geschrieben wird.
Und hier ist der Inhalt, um in die Datei zu schreiben:
JP日本-八洲In diesem Beispiel verwenden wir UTF-16 OutputStreamWriter , um die Zeichen in einer Datei zu schreiben, und verwenden dann FileInputStream um jede Daten byte dieser Datei zu lesen.
OutputStreamWriter_UTF16_Ex1.java
package org.o7planning.outputstreamwriter.ex;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.nio.charset.StandardCharsets;
public class OutputStreamWriter_UTF16_Ex1 {
private static final String filePath = "/Volumes/Data/test/utf16-file-out.txt";
public static void main(String[] args) throws IOException {
System.out.println(" --- Write UTF-16 File --- ");
write_UTF16_Character_Stream();
System.out.println(" --- Read File as Binary Stream --- ");
readAs_Binary_Stream();
}
private static void write_UTF16_Character_Stream() throws IOException {
File outFile = new File(filePath);
outFile.getParentFile().mkdirs(); // Create parent folder.
// Create OutputStream to write a file.
OutputStream os = new FileOutputStream(outFile);
// Create a OutputStreamWriter
OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_16);
String s = "JP日本-八洲";
osw.write(s);
osw.close();
}
private static void readAs_Binary_Stream() throws IOException {
InputStream is = new FileInputStream(filePath);
int byteValue;
while ((byteValue = is.read()) != -1) { // Read byte by byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Write UTF-16 File ---
--- Read File as Binary Stream ---
þ 254
ÿ 255
0
J 74
0
P 80
e 101
å 229
g 103
, 44
0
- 45
Q 81
k 107
m 109
2 50Im Java hat das Datentyp char die Größe von 2 bytes, und UTF-16 wird zum Kodieren vom Typ String verwendet. Das Bild unten zeigt die Zeichen in OutputStreamWriter:
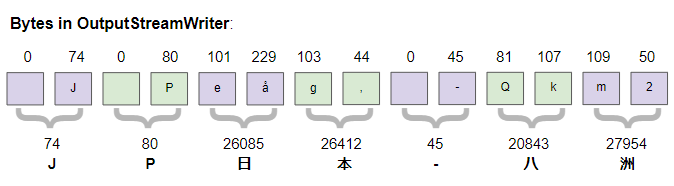
Die Analyse der bytes auf die neu erstellten Datei zeigt: die 2 ersten bytes(254, 255) werden verwendet, um zu markieren, dass das ein UTF-16 kodierter Text ist. Sie werden auch als BOM (Byte Order Mark) bezeichnet, die nächsten bytes sind so gleich wie bytes im OutputStreamWriter.

3. UTF-8 OutputStreamWriter
UTF-8 ist die weltweit üblichste Kodierung (encoding). Es kann alle Schriftarten der Welt kodieren, einschließlich chinesischer und japanischer Schriftarten. Ab Java5 war UTF-8 die Standardkodierung zum Lesen und Schreiben von Dateien.
Die von Java generierte Dateien UTF-8 haben keine BOM (Byte Order Mark) (die ersten bytes der Datei zum markieren, dass es sich um eine Datei UTF-8 handelt).
OutputStreamWriter_UTF8_Ex1.java
package org.o7planning.outputstreamwriter.ex;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.nio.charset.StandardCharsets;
public class OutputStreamWriter_UTF8_Ex1 {
private static final String filePath = "/Volumes/Data/test/utf8-file-out.txt";
public static void main(String[] args) throws IOException {
System.out.println(" --- Write UTF-8 File --- ");
write_UTF8_Character_Stream();
System.out.println(" --- Read File as Binary Stream --- ");
readAs_Binary_Stream();
}
private static void write_UTF8_Character_Stream() throws IOException {
File outFile = new File(filePath);
outFile.getParentFile().mkdirs(); // Create parent folder.
// Create OutputStream to write a file.
OutputStream os = new FileOutputStream(outFile);
// Create a OutputStreamWriter
OutputStreamWriter osw = new OutputStreamWriter(os, StandardCharsets.UTF_8);
String s = "JP日本-八洲";
osw.write(s);
osw.close();
}
private static void readAs_Binary_Stream() throws IOException {
InputStream is = new FileInputStream(filePath);
int byteValue;
while ((byteValue = is.read()) != -1) { // Read byte by byte.
System.out.println((char) byteValue + " " + byteValue);
}
is.close();
}
}Output:
--- Write UTF-8 File ---
--- Read File as Binary Stream ---
J 74
P 80
æ 230
151
¥ 165
æ 230
156
¬ 172
- 45
å 229
133
« 171
æ 230
´ 180
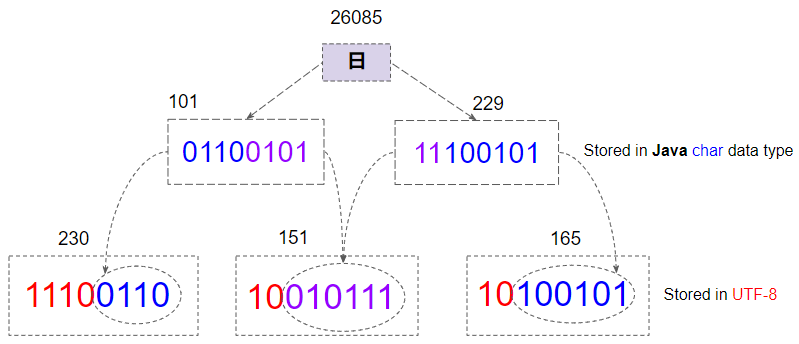
² 178Im Java ist der Datentypchar 2 bytes groß und UTF-16 wird verwendet um das Typ String zu kodieren. Das Bild unten zeigt die Zeichen in OutputStreamWriter:
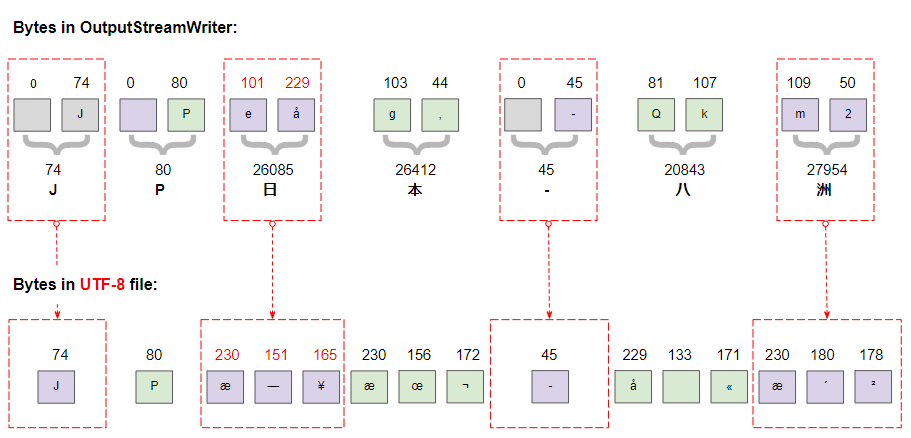
UTF-8 wird viel komplexer als UTF-16 kodiert und es verwendet 1, 2, 3 oder 4 bytes zum Speichern eines Zeichens. Eine detaillierte Analyse der bytes in der neu erstellten Datei UTF-8 zeigt dieses Ding deutlich.
Number of bytes | From | To | Byte 1 | Byte 2 | Byte 3 | Byte 4 | ||
1 | U+0000 | 0 | U+007F | 127 | 0xxxxxxx | |||
2 | U+0080 | 128 | U+07FF | 2047 | 110xxxxx | 10xxxxxx | ||
3 | U+0800 | 2048 | U+FFFF | 65535 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
4 | U+10000 | 65536 | U+10FFFF | 1114111 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Z.B: Das Zeichen "日" hat die Kodenummer von 26085 , die zum Bereich [2048,65535] gehört. UTF-8 braucht 3 bytes um es zu speichern.
Die Anleitungen Java IO
- Die Anleitung zu Java CharArrayWriter
- Die Anleitung zu Java FilterReader
- Die Anleitung zu Java FilterWriter
- Die Anleitung zu Java PrintStream
- Die Anleitung zu Java BufferedReader
- Die Anleitung zu Java BufferedWriter
- Die Anleitung zu Java StringReader
- Die Anleitung zu Java StringWriter
- Die Anleitung zu Java PipedReader
- Die Anleitung zu Java LineNumberReader
- Die Anleitung zu Java PushbackReader
- Die Anleitung zu Java PrintWriter
- Die Anleitung zu Java IO Binary Streams
- Die Anleitung zu Java IO Character Streams
- Die Anleitung zu Java BufferedOutputStream
- Die Anleitung zu Java ByteArrayOutputStream
- Die Anleitung zu Java DataOutputStream
- Die Anleitung zu Java PipedInputStream
- Die Anleitung zu Java OutputStream
- Die Anleitung zu Java ObjectOutputStream
- Die Anleitung zu Java PushbackInputStream
- Die Anleitung zu Java SequenceInputStream
- Die Anleitung zu Java BufferedInputStream
- Die Anleitung zu Java Reader
- Die Anleitung zu Java Writer
- Die Anleitung zu Java FileReader
- Die Anleitung zu Java FileWriter
- Die Anleitung zu Java CharArrayReader
- Die Anleitung zu Java ByteArrayInputStream
- Die Anleitung zu Java DataInputStream
- Die Anleitung zu Java ObjectInputStream
- Die Anleitung zu Java InputStreamReader
- Die Anleitung zu Java OutputStreamWriter
- Die Anleitung zu Java InputStream
- Die Anleitung zu Java FileInputStream
Show More
- Anleitungen Java Servlet/JSP
- Die Anleitungen Java New IO
- Anleitungen Spring Cloud
- Die Anleitungen Oracle Java ADF
- Die Anleitungen Java Collections Framework
- Java Grundlagen
- Die Anleitungen Java Date Time
- Java Open Source Bibliotheken
- Anleitungen Java Web Services
- Die Anleitungen Struts2 Framework
- Anleitungen Spring Boot