Die Anleitung zu Java Reguläre Ausdrücke
1. Die Regulären Ausdrücke (Regular expression)
Ein Regelmäßiger Ausdruck (Regular expressions) definiert eine Vorlage (pattern) der Suche von der Kette. Sie ist benutzt, um eine Text zu suchen, ändern und bearbeiten. Die vom regelmäßigen Ausdruck definierte Vorlage können zu einer vorher gegebenen Text einmal oder vielmals passen oder nicht passen.
Die Abkürzung von dem regelmäßigen Ausdruck (regular expressions) is regex.
Die Abkürzung von dem regelmäßigen Ausdruck (regular expressions) is regex.
Die Regular Expression werden von den meisten Programmierungssprache unterstützt. Zum Beispiel sind das Java, C#, C/C++, usw... Leider unterstützt jede Sprache die Regular expression in ihrem eigenen unterschiedlichen Weg
Sie könnten die Interest daran haben:
2. Die Regelung um die regular expression zu schreiben
No | Die regulären Ausdruck | Die Bezeichnung |
1 | . | Irgendeinem Zeichen entsprechen (match) |
2 | ^regex | Die reguläre Ausdruck muss bei der Startspunkt der Linie entsprechen |
3 | regex$ | Die reguläre Ausdruck muss bei der Ende der Linie entsprechen |
4 | [abc] | Die Definition einstellen, die a oder b oder c entsprechen. |
5 | [abc][vz] | Die Definition einstellen, die a oder b oder c entsprechen, danach kommt v oder z. |
6 | [^abc] | Wenn das Zeichen ^ als den ersten Charakter in eckige Klammer auftritt, verneint es das Modell. Das kann allen Zeicher außer a oder b oder c entsprechen |
7 | [a-d1-7] | Der Raum: eine Buchstabe zwischen a und d und die Zahlen vom 1 bis 7 entsprechen |
8 | X|Z | X oder Z finden |
9 | XZ | X und folgend Z finden |
10 | $ | Die Zeileende prüfen |
11 | \d | Irgendeines Digit, für |
12 | \D | Die nicht-Digit, für [^0-9] verküzen |
13 | \s | Ein Leerzeichen, für [ \t\n\x0b\r\f] verküzen |
14 | \S | Ein Nicht-Leerzeichen, für [^\s] verküzen |
15 | \w | Eine Buchstabe, für [a-zA-Z_0-9] verküzen |
16 | \W | Eine Nicht-Buchstabe, für [^\w] verküzen |
17 | \S+ | Einige Nicht Leerzeichen (ein oder mehr) |
18 | \b | Das zeichen vom a-z oder A-Z oder 0-9 oder _, für [a-zA-Z0-9_] verküzen. |
19 | * | Zero oder mehrmals auftreten, für {0,} verküzen |
20 | + | Eins oder mehrmals auftreten, für {1,} verküzen |
21 | ? | Zero oder einsmal auftreten ? für {0,1}. verküzen |
22 | {X} | X Mals auftreten {} |
23 | {X,Y} | Vom X zum Y Mals auftreten |
24 | *? | * bedeutet das Auftritt in zero oder mehrmals,? am hinter bedeutet die Suche nach der kleinste Übereinstimmung |
3. Die besonderen Zeichen im Java Regex (Special characters)
Einige besonderen Zeichen in Java Regex:
\.[{(*+?^$|Die obengewähnten Zeichen sind die besonderen Zeichen. Im Java Regex: Wenn Sie diese besonderen Zeichen in dem normalen Weg verstehen möchten, brauchen Sie die Merkzeichen \ vor der Zeichen hinzufügen.
Zum Beispiel. die Zeichen Punkt (.) versteht java regex irgendeine Zeichen. Wenn Sie möchten, java regex versteht as eine normale Punkt, brauchen Sie die \ vor ihr hinzufügen.
Zum Beispiel. die Zeichen Punkt (.) versteht java regex irgendeine Zeichen. Wenn Sie möchten, java regex versteht as eine normale Punkt, brauchen Sie die \ vor ihr hinzufügen.
// Regex pattern describe any character.
String regex = ".";
// Regex pattern describe a dot character.
String regex = "\\.";4. String.matches(String) benutzen
- Class String
...
// Check the entire String object matches the regex or not.
public boolean matches(String regex)
..Method String.matches(String regex) ermöglicht Ihnen zu checken, ob die alle String zu einer regex passen oder nicht. Das ist die üblichste Maßnahme. Sehen Sie die Beispiele
StringMatches.java
package org.o7planning.tutorial.regex.stringmatches;
public class StringMatches {
public static void main(String[] args) {
String s1 = "a";
System.out.println("s1=" + s1);
// Check the entire s1
// Match any character
// Rule .
// ==> true
boolean match = s1.matches(".");
System.out.println("-Match . " + match);
s1 = "abc";
System.out.println("s1=" + s1);
// Check the entire s1
// Match any character
// Rule .
// ==> false (Because s1 has three characters)
match = s1.matches(".");
System.out.println("-Match . " + match);
// Check the entire s1
// Match with any character 0 or more times
// Combine the rules . and *
// ==> true
match = s1.matches(".*");
System.out.println("-Match .* " + match);
String s2 = "m";
System.out.println("s2=" + s2);
// Check the entire s2
// Start by m
// Rule ^
// ==> true
match = s2.matches("^m");
System.out.println("-Match ^m " + match);
s2 = "mnp";
System.out.println("s2=" + s2);
// Check the entire s2
// Start by m
// Rule ^
// ==> false (Because s2 has three characters)
match = s2.matches("^m");
System.out.println("-Match ^m " + match);
// Start by m
// Next any character, appearing one or more times.
// Rule ^ and. and +
// ==> true
match = s2.matches("^m.+");
System.out.println("-Match ^m.+ " + match);
String s3 = "p";
System.out.println("s3=" + s3);
// Check s3 ending with p
// Rule $
// ==> true
match = s3.matches("p$");
System.out.println("-Match p$ " + match);
s3 = "2nnp";
System.out.println("s3=" + s3);
// Check the entire s3
// End of p
// ==> false (Because s3 has 4 characters)
match = s3.matches("p$");
System.out.println("-Match p$ " + match);
// Check out the entire s3
// Any character appearing once.
// Followed by n, appear one or up to three times.
// End by p: p $
// Combine the rules: . , {X, y}, $
// ==> true
match = s3.matches(".n{1,3}p$");
System.out.println("-Match .n{1,3}p$ " + match);
String s4 = "2ybcd";
System.out.println("s4=" + s4);
// Start by 2
// Next x or y or z
// Followed by any one or more times.
// Combine the rules: [abc]. , +
// ==> true
match = s4.matches("2[xyz].+");
System.out.println("-Match 2[xyz].+ " + match);
String s5 = "2bkbv";
// Start any one or more times
// Followed by a or b, or c: [abc]
// Next z or v: [zv]
// Followed by any
// ==> true
match = s5.matches(".+[abc][zv].*");
System.out.println("-Match .+[abc][zv].* " + match);
}
}Das Ergebnis von dem Beispiel
s1=a
-Match . true
s1=abc
-Match . false
-Match .* true
s2=m
-Match ^m true
s2=mnp
-Match ^m false
-Match ^m.+ true
s3=p
-Match p$ true
s3=2nnp
-Match p$ false
-Match .n{1,3}p$ true
s4=2ybcd
-Match 2[xyz].+ true
-Match .+[abc][zv].* trueSplitWithRegex.java
package org.o7planning.tutorial.regex.stringmatches;
public class SplitWithRegex {
public static final String TEXT = "This is my text";
public static void main(String[] args) {
System.out.println("TEXT=" + TEXT);
// White space appears one or more times.
// The whitespace characters: \t \n \x0b \r \f
// Combining rules: \ s and +
String regex = "\\s+";
String[] splitString = TEXT.split(regex);
// 4
System.out.println(splitString.length);
for (String string : splitString) {
System.out.println(string);
}
// Replace all whitespace with tabs
String newText = TEXT.replaceAll("\\s+", "\t");
System.out.println("New text=" + newText);
}
}Das Ergebnis von dem Beispiel
TEXT=This is my text
4
This
is
my
text
New text=This is my textEitherOrCheck.java
package org.o7planning.tutorial.regex.stringmatches;
public class EitherOrCheck {
public static void main(String[] args) {
String s = "The film Tom and Jerry!";
// Check the whole s
// Begin by any characters appear 0 or more times
// Next Tom or Jerry
// End with any characters appear 0 or more times
// Combine the rules:., *, X | Z
// ==> true
boolean match = s.matches(".*(Tom|Jerry).*");
System.out.println("s=" + s);
System.out.println("-Match .*(Tom|Jerry).* " + match);
s = "The cat";
// ==> false
match = s.matches(".*(Tom|Jerry).*");
System.out.println("s=" + s);
System.out.println("-Match .*(Tom|Jerry).* " + match);
s = "The Tom cat";
// ==> true
match = s.matches(".*(Tom|Jerry).*");
System.out.println("s=" + s);
System.out.println("-Match .*(Tom|Jerry).* " + match);
}
}Das Ergebni von dem Beispiel
s=The film Tom and Jerry!
-Match .*(Tom|Jerry).* true
s=The cat
-Match .*(Tom|Jerry).* false
s=The Tom cat
-Match .*(Tom|Jerry).* true5. Pattern und Matcher benutzen
1. Pattern ist ein Vorlage Objekt, eine aus der regular expression kompilierte Version. Es hat keine public Constructor und wir benutzen eine static method compile(String) um einen Objekt zu erstellen ( der Parameter ist die regular expression).
2. Matcher ist ein Mittel zu checken, ob die Input Datenreihe zum oben erstellten Objekt Pattern passt oder nicht. Diese Class hat keine public constructor. Und wir nehmen diesen Objejt durch die method matcher(String) des Objekt Pattern. Und der Eingabeparameter String ist die Text, die ist zu checken
3.PatternSyntaxException wird geworfen wenn die regular expression nicht genau ist.
2. Matcher ist ein Mittel zu checken, ob die Input Datenreihe zum oben erstellten Objekt Pattern passt oder nicht. Diese Class hat keine public constructor. Und wir nehmen diesen Objejt durch die method matcher(String) des Objekt Pattern. Und der Eingabeparameter String ist die Text, die ist zu checken
3.PatternSyntaxException wird geworfen wenn die regular expression nicht genau ist.
String regex= ".xx.";
// Create a Pattern object through a static method.
Pattern pattern = Pattern.compile(regex);
// Get a Matcher object
Matcher matcher = pattern.matcher("MxxY");
boolean match = matcher.matches();
System.out.println("Match "+ match);- Class Pattern:
public static Pattern compile(String regex, int flags) ;
public static Pattern compile(String regex);
public Matcher matcher(CharSequence input);
public static boolean matches(String regex, CharSequence input);- Class Matcher:
public int start()
public int start(int group)
public int end()
public int end(int group)
public String group()
public String group(int group)
public String group(String name)
public int groupCount()
public boolean matches()
public boolean lookingAt()
public boolean find()Das ist ein Beispiel für die Benutzung Matcher und die Method find(), um die untergeordneten Kette zu finden, die zu einer regular expression passen
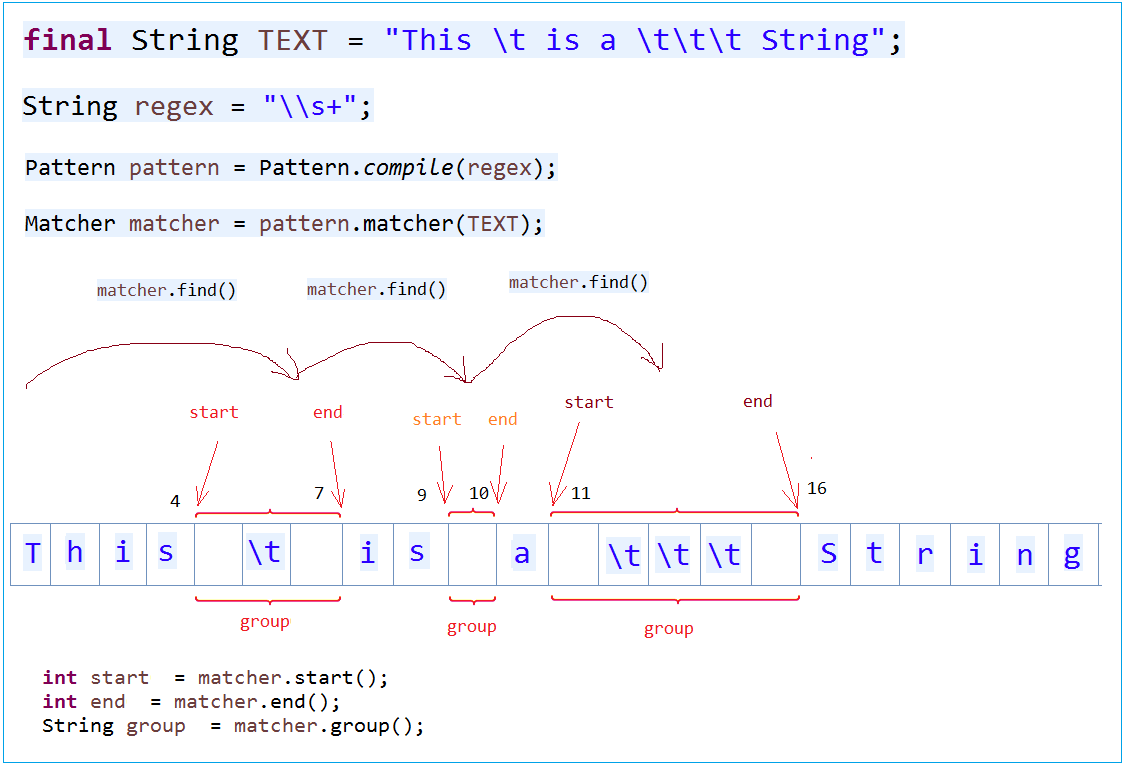
MatcherFind.java
package org.o7planning.tutorial.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MatcherFind {
public static void main(String[] args) {
final String TEXT = "This \t is a \t\t\t String";
// Spaces appears one or more time.
String regex = "\\s+";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(TEXT);
int i = 0;
while (matcher.find()) {
System.out.print("start" + i + " = " + matcher.start());
System.out.print(" end" + i + " = " + matcher.end());
System.out.println(" group" + i + " = " + matcher.group());
i++;
}
}
}Das Ergebnis vom Beispiel
start = 4 end = 7 group =
start = 9 end = 10 group =
start = 11 end = 16 group =Method Matcher.lookingAt()
MatcherLookingAt.java
package org.o7planning.tutorial.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MatcherLookingAt {
public static void main(String[] args) {
String country1 = "iran";
String country2 = "Iraq";
// Start by I followed by any character.
// Following is the letter a or e.
String regex = "^I.[ae]";
Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(country1);
// lookingAt () searches that match the first part.
System.out.println("lookingAt = " + matcher.lookingAt());
// matches() must be matching the entire
System.out.println("matches = " + matcher.matches());
// Reset matcher with new text: country2
matcher.reset(country2);
System.out.println("lookingAt = " + matcher.lookingAt());
System.out.println("matches = " + matcher.matches());
}
}6. Die Gruppe (Group)
Eine Regular Expression können Sie in die Gruppe trennen (group):
// A regular expression
String regex = "\\s+=\\d+";
// Writing as three group, by marking ()
String regex2 = "(\\s+)(=)(\\d+)";
// Two group
String regex3 = "(\\s+)(=\\d+)";Die Gruppe können miteinander einnisten. Deshalb brauchen wir eine Regelung um die Index der Gruppe zu markieren. Alle Pattern werden als die Gruppe 0 definiert. Und die restlichen Gruppe werden wie in die folgenden Illustration bezeichnet

Beachten Sie: (?:pattern) benutzen, um Java eine None-capturing group zu informieren
Ab Java 7 können Sie eine Gruppe mit einem Name bestimmen (?<name>pattern), Und Sie können die Inhalte zugreifen, die zu Matcher.group(String name) passen. Das macht Regex länger aber die Code ist sinnvoller und einfacher
Die Gruppe nach dem Name kann durch Matcher.group(int group) mit der ähnlichen Index zugegriffen werden.
Java bildet nur vom Name zur Index der Gruppe ab. Deshalb können Sie den gleichen Name für 2 unterschiedliche Gruppen nicht benutzen
Die Gruppe nach dem Name kann durch Matcher.group(int group) mit der ähnlichen Index zugegriffen werden.
Java bildet nur vom Name zur Index der Gruppe ab. Deshalb können Sie den gleichen Name für 2 unterschiedliche Gruppen nicht benutzen
-
Sehen Sie ein Beispiel über die Stellung des Name für die Gruppe (Java >=7)
NamedGroup.java
package org.o7planning.tutorial.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class NamedGroup {
public static void main(String[] args) {
final String TEXT = " int a = 100;float b= 130;float c= 110 ; ";
// Use (?<groupName>pattern) to define a group named: groupName
// Defined group named declare: using (?<declare>...)
// And a group named value: use: (?<value>..)
String regex = "(?<declare>\\s*(int|float)\\s+[a-z]\\s*)=(?<value>\\s*\\d+\\s*);";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(TEXT);
while (matcher.find()) {
String group = matcher.group();
System.out.println(group);
System.out.println("declare: " + matcher.group("declare"));
System.out.println("value: " + matcher.group("value"));
System.out.println("------------------------------");
}
}
}Das Ergebnis von dem Beispiel:
int a = 100;
declare: int a
value: 100
------------------------------
float b= 130;
declare: float b
value: 130
------------------------------
float c= 110 ;
declare: float c
value: 110
------------------------------Sie können die Image wie folgend sehen

7. Pattern, Matcher, Group und *? benutzen
In einigen Fälle ist *? sehr wichtig. Sehen Sie ein Beispiel:
// This is a regex
// any characters appear 0 or more times,
// followed by ' and >
String regex = ".*'>";
// TEXT1 match the regex.
String TEXT1 = "FILE1'>";
// And TEXT2 match the regex
String TEXT2 = "FILE1'> <a href='http://HOST/file/FILE2'>";
*? wird einen kleinsten Zusammenklang finden. Sehen wir das folgende Beispiel:
NamedGroup2.java
package org.o7planning.tutorial.regex;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class NamedGroup2 {
public static void main(String[] args) {
String TEXT = "<a href='http://HOST/file/FILE1'>File 1</a>"
+ "<a href='http://HOST/file/FILE2'>File 2</a>";
// Java >= 7.
// Define group named fileName.
// *? ==> ? after a quantifier makes it a reluctant quantifier.
// It tries to find the smallest match.
String regex = "/file/(?<fileName>.*?)'>";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(TEXT);
while (matcher.find()) {
System.out.println("File Name = " + matcher.group("fileName"));
}
}
}Das Ergebnis von dem Beispiel
File Name = FILE1
File Name = FILE2Java Grundlagen
- Anpassen von Java-Compiler, der Ihre Annotation verarbeitet (Annotation Processing Tool)
- Java Programmierung für Team mit Eclipse und SVN
- Die Anleitung zu Java WeakReference
- Die Anleitung zu Java PhantomReference
- Komprimierung und Dekomprimierung in Java
- Konfigurieren von Eclipse zur Verwendung des JDK anstelle von JRE
- Java-Methoden String.format() und printf()
- Syntax und neue Funktionen in Java 8
- Die Anleitung zu Java Reguläre Ausdrücke
- Die Anleitung zu Java Multithreading Programming
- JDBC Driver Bibliotheken für verschiedene Arten von Datenbank in Java
- Die Anleitung zu Java JDBC
- Holen Sie sich die automatisch erhöhenden Wert der Spalte bei dem Insert eines Rekord, der JDBC benutzt
- Die Anleitung zu Java Stream
- Die Anleitung zu Java Functional Interface
- Einführung in Raspberry Pi
- Die Anleitung zu Java Predicate
- Abstrakte Klasse und Interface in Java
- Zugriffsmodifikatoren (Access modifiers) in Java
- Die Anleitung zu Java Enum
- Die Anleitung zu Java Annotation
- Vergleichen und Sortieren in Java
- Die Anleitung zu Java String, StringBuffer und StringBuilder
- Die Anleitung zu Java Exception
- Die Anleitung zu Java Generics
- Manipulieren von Dateien und Verzeichnissen in Java
- Die Anleitung zu Java BiPredicate
- Die Anleitung zu Java Consumer
- Die Anleitung zu Java BiConsumer
- Was ist erforderlich, um mit Java zu beginnen?
- Geschichte von Java und der Unterschied zwischen Oracle JDK und OpenJDK
- Installieren Sie Java unter Windows
- Installieren Sie Java unter Ubuntu
- Installieren Sie OpenJDK unter Ubuntu
- Installieren Sie Eclipse
- Installieren Sie Eclipse unter Ubuntu
- Schnelle lernen Java für Anfänger
- Geschichte von Bits und Bytes in der Informatik
- Datentypen in Java
- Bitweise Operationen
- if else Anweisung in Java
- Switch Anweisung in Java
- Schleifen in Java
- Die Anleitung zu Java Array
- JDK Javadoc im CHM-Format
- Vererbung und Polymorphismus in Java
- Die Anleitung zu Java Function
- Die Anleitung zu Java BiFunction
- Beispiel für Java Encoding und Decoding mit Apache Base64
- Die Anleitung zu Java Reflection
- Java-Remote-Methodenaufruf - Java RMI
- Die Anleitung zu Java Socket
- Welche Plattform sollten Sie wählen für Applikationen Java Desktop entwickeln?
- Die Anleitung zu Java Commons IO
- Die Anleitung zu Java Commons Email
- Die Anleitung zu Java Commons Logging
- Java System.identityHashCode, Object.hashCode und Object.equals verstehen
- Die Anleitung zu Java SoftReference
- Die Anleitung zu Java Supplier
- Java Aspect Oriented Programming mit AspectJ (AOP)
Show More
- Anleitungen Java Servlet/JSP
- Die Anleitungen Java Collections Framework
- Java API für HTML & XML
- Die Anleitungen Java IO
- Die Anleitungen Java Date Time
- Anleitungen Spring Boot
- Anleitungen Maven
- Anleitungen Gradle
- Anleitungen Java Web Services
- Anleitungen Java SWT
- Die Anleitungen JavaFX
- Die Anleitungen Oracle Java ADF
- Die Anleitungen Struts2 Framework
- Anleitungen Spring Cloud